文字列から浮動小数点数に変換する、なるべく速く
TL;DR
文字列から浮動小数点数に変換するならfastfloat使いましょう。
私が試せる環境で比較する限り、とても速いです。
細かいことが気になります
C++でちょっとしたプログラムを書くときにいつも気になるのが
「文字列データから指定データ型への変換処理をどうやって効率的に書くか」
です。私だけかもしれませんが。
特に悩んでしまうのが「文字列→浮動小数点」です。
- std::scanf, std::stringstreamを使うものは大抵すごく遅い
std::strtodstd::stodはstd::stringへの変換が入るので避けたい- std::from_charsは(libstdc++が)浮動小数点型に対応していない
- boost::sprit::qiが何故か速いのだけれどこのためにboost::sprit使うのは重い
と色々制約が多いのです。どうにかならないものか。
fast_floatの紹介
…と思っていたら見付けたのがsimdjsonの作者であるlemireさんが開発しているfast_floatです。 github.com
もともとはfast_double_parserとして開発されいて、こちらはGo言語に移植されてstrconv.ParseFloat として標準化されているようですね。そんな経緯があるとは知らなんだ。
Microsoft LightGBMでも利用されているようで。
GitHub - lemire/fast_double_parser: Fast function to parse strings into double (binary64) floating-point values, enforces the RFC 7159 (JSON standard) grammar: 4x faster than strtod
このfast_double_parserをstd::from_charsのAPIに寄せて書き直したものがfast_floatになります。
こちらの実装はApache ArrowやYandex ClickHouseに利用されているようですね。モテモテ。
さらに最近lemire/fast_floatからfastfloat/fast_floatに移動して、少しずつですが更に高速化しています。
ベンチマークのプログラムの準備
「どのくらい速いのか?」については、lemireさんがベンチマークを公開しています。
github.com
ベンチマークを実行すると以下のライブラリのランダムな浮動小数点数表記の文字列のdoubleへの変換速度を計測してくれます。
- double conversion https://github.com/google/double-conversion
- netlib http://www.netlib.org/fp/の関数名を変更したもの
- strtod C++の標準ライブラリ
- abseil https://github.com/abseil/abseil-cpp内の
absl::from_chars
このベンチマークを実行するだけだと芸がないので、以下のベンチマークも追加しています。
- boost::spirit:qi
- fast_float (fixed) 指数表記以外の10進数表記に対応したロジック
GitHub - toge/simple_fastfloat_benchmark
ベンチマークのコードは、コードを内包したりCMakeのFetchContent機能を使っているので、ライブラリを別途インストールする必要ありません。
git, cmake, gccがあれば、お手軽に試せます。
git clone https://github.com/toge/simple_fastfloat_benchmark cd simple_float_benchmark export CXXFLAGS="-O3 -march=native" cmake -B build . cmake --build build --config Release build/benchmarks/benchmark
ベンチマークの結果
fastfloat (fake)っていうのは「パースだけして数値計算しない」ロジックなので理論値みたいなものですかね。
AMD Ryzen 1700(自作PC) gcc 10.2.1
fastfloat (fake) : 1595.02 MB/s (+/- 3.7 %) 76.02 Mfloat/s 9.14 i/B 201.00 i/f (+/- 0.0 %) 0.00 bm/B 0.00 bm/f (+/- 76.1 %) 1.99 c/B 43.75 c/f (+/- 3.3 %) 4.59 i/c 3.33 GHz netlib : 215.83 MB/s (+/- 2.5 %) 10.29 Mfloat/s 32.26 i/B 709.76 i/f (+/- 0.0 %) 0.19 bm/B 4.14 bm/f (+/- 0.1 %) 14.70 c/B 323.33 c/f (+/- 2.2 %) 2.20 i/c 3.33 GHz doubleconversion : 130.89 MB/s (+/- 3.2 %) 6.24 Mfloat/s 56.35 i/B 1239.78 i/f (+/- 0.0 %) 0.12 bm/B 2.75 bm/f (+/- 2.0 %) 24.26 c/B 533.80 c/f (+/- 3.0 %) 2.32 i/c 3.33 GHz strtod : 141.70 MB/s (+/- 1.9 %) 6.75 Mfloat/s 51.91 i/B 1142.06 i/f (+/- 0.0 %) 0.13 bm/B 2.79 bm/f (+/- 0.3 %) 22.45 c/B 493.82 c/f (+/- 1.5 %) 2.31 i/c 3.34 GHz abseil : 342.08 MB/s (+/- 5.3 %) 16.30 Mfloat/s 30.11 i/B 662.51 i/f (+/- 0.0 %) 0.02 bm/B 0.50 bm/f (+/- 14.1 %) 9.27 c/B 203.92 c/f (+/- 5.2 %) 3.25 i/c 3.32 GHz boost sprit qi : 585.51 MB/s (+/- 5.7 %) 27.91 Mfloat/s 24.86 i/B 547.00 i/f (+/- 0.0 %) 0.00 bm/B 0.00 bm/f (+/- 72.1 %) 5.42 c/B 119.23 c/f (+/- 5.3 %) 4.59 i/c 3.33 GHz fastfloat : 1116.40 MB/s (+/- 5.9 %) 53.21 Mfloat/s 11.64 i/B 256.04 i/f (+/- 0.0 %) 0.00 bm/B 0.01 bm/f (+/- 2.6 %) 2.85 c/B 62.61 c/f (+/- 5.3 %) 4.09 i/c 3.33 GHz fastfloat fixed : 1339.68 MB/s (+/- 2.5 %) 63.85 Mfloat/s 9.86 i/B 217.02 i/f (+/- 0.0 %) 0.00 bm/B 0.00 bm/f (+/- 3.9 %) 2.38 c/B 52.27 c/f (+/- 1.7 %) 4.15 i/c 3.34 GHz
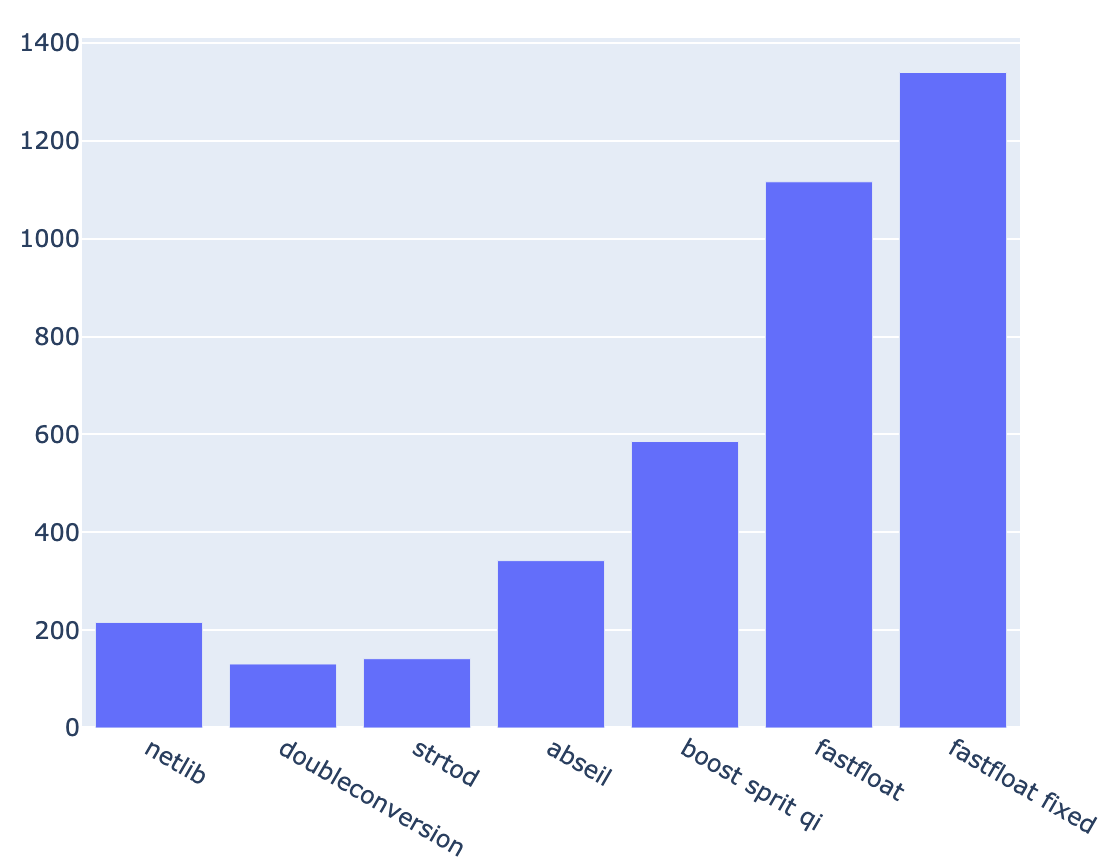
Linuxだとperfの計測結果まで付与してくれて便利ですね。 Zen3でどうなるのか気になる…。(Ryzen 5800Xください)
Intel Core i5-8210Y(Macbook Air 2018) apple-clang 12.0.0
fastfloat (fake) : 1314.89 MB/s (+/- 19.2 %) 62.67 Mfloat/s 15.96 ns/f netlib : 262.55 MB/s (+/- 16.2 %) 12.51 Mfloat/s 79.91 ns/f doubleconversion : 220.23 MB/s (+/- 17.5 %) 10.50 Mfloat/s 95.27 ns/f strtod : 67.26 MB/s (+/- 9.2 %) 3.21 Mfloat/s 311.92 ns/f abseil : 412.25 MB/s (+/- 13.9 %) 19.65 Mfloat/s 50.89 ns/f boost spirit qi : 426.88 MB/s (+/- 14.3 %) 20.35 Mfloat/s 49.15 ns/f fastfloat : 886.46 MB/s (+/- 14.2 %) 42.25 Mfloat/s 23.67 ns/f fastfloat fixed : 1076.13 MB/s (+/- 18.9 %) 51.29 Mfloat/s 19.50 ns/f
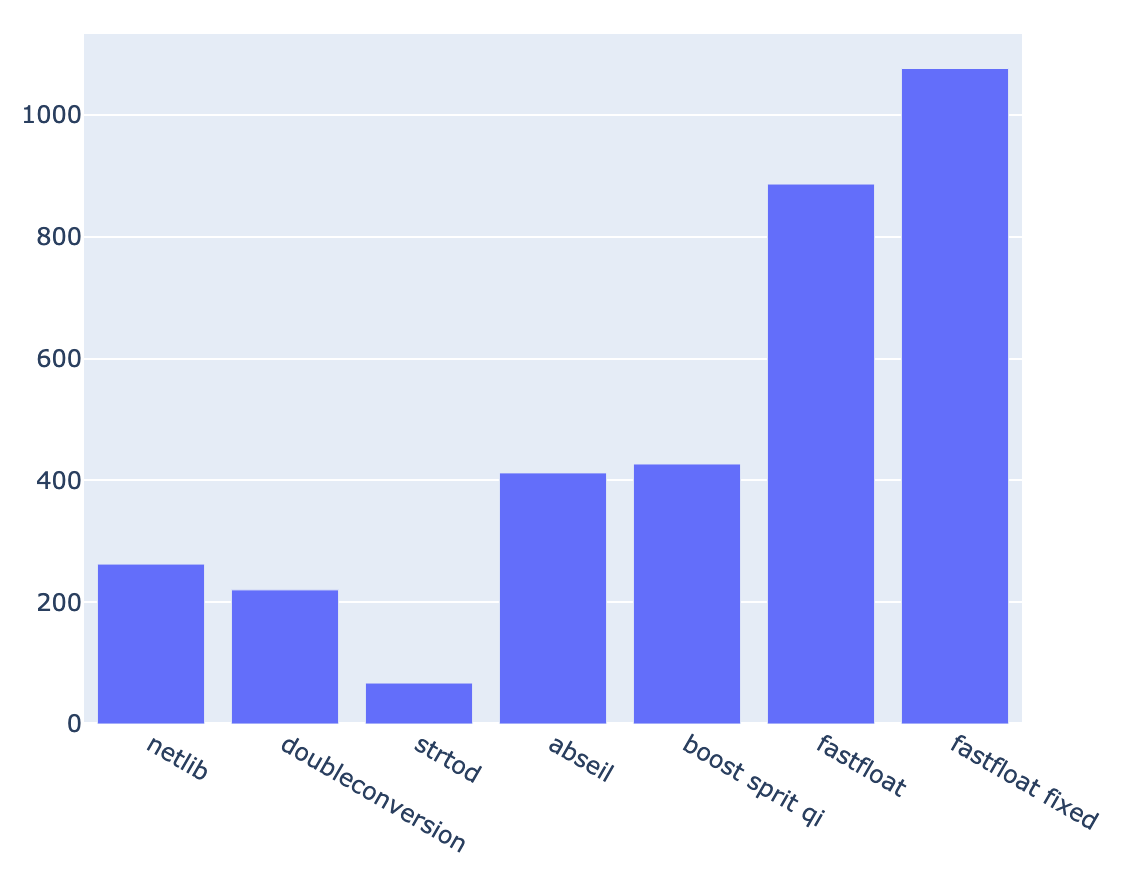
MacOS Xだからperfがないのであっさり表示。
strtodの衝撃の遅さが目を惹きます。
Intel Core i5-4300U(Let's Note LX3) gcc 10.2.0
fastfloat (fake) : 885.05 MB/s (+/- 3.7 %) 42.18 Mfloat/s 9.59 i/B 211.00 i/f (+/- 0.0 %) 0.00 bm/B 0.00 bm/f (+/- 47.6 %) 3.11 c/B 68.32 c/f (+/- 1.0 %) 3.09 i/c 2.88 GHz netlib : 197.58 MB/s (+/- 1.6 %) 9.42 Mfloat/s 30.46 i/B 670.18 i/f (+/- 0.0 %) 0.19 bm/B 4.12 bm/f (+/- 5.1 %) 13.94 c/B 306.64 c/f (+/- 0.8 %) 2.19 i/c 2.89 GHz doubleconversion : 146.04 MB/s (+/- 1.3 %) 6.96 Mfloat/s 50.79 i/B 1117.40 i/f (+/- 0.0 %) 0.12 bm/B 2.58 bm/f (+/- 0.5 %) 18.86 c/B 414.93 c/f (+/- 0.6 %) 2.69 i/c 2.89 GHz strtod : 126.60 MB/s (+/- 1.2 %) 6.03 Mfloat/s 51.72 i/B 1137.85 i/f (+/- 0.0 %) 0.15 bm/B 3.20 bm/f (+/- 0.2 %) 21.76 c/B 478.70 c/f (+/- 0.5 %) 2.38 i/c 2.89 GHz abseil : 363.70 MB/s (+/- 1.3 %) 17.33 Mfloat/s 26.93 i/B 592.50 i/f (+/- 0.0 %) 0.02 bm/B 0.50 bm/f (+/- 0.3 %) 7.58 c/B 166.69 c/f (+/- 0.5 %) 3.55 i/c 2.89 GHz boost spirit qi : 543.73 MB/s (+/- 1.2 %) 25.92 Mfloat/s 21.09 i/B 464.00 i/f (+/- 0.0 %) 0.00 bm/B 0.00 bm/f (+/- 53.3 %) 5.07 c/B 111.44 c/f (+/- 0.2 %) 4.16 i/c 2.89 GHz fastfloat : 729.81 MB/s (+/- 1.7 %) 34.78 Mfloat/s 12.14 i/B 267.04 i/f (+/- 0.0 %) 0.00 bm/B 0.01 bm/f (+/- 0.5 %) 3.78 c/B 83.11 c/f (+/- 0.3 %) 3.21 i/c 2.89 GHz fastfloat fixed : 824.43 MB/s (+/- 1.3 %) 39.29 Mfloat/s 10.23 i/B 225.02 i/f (+/- 0.0 %) 0.00 bm/B 0.00 bm/f (+/- 1.3 %) 3.34 c/B 73.54 c/f (+/- 0.4 %) 3.06 i/c 2.89 GHz
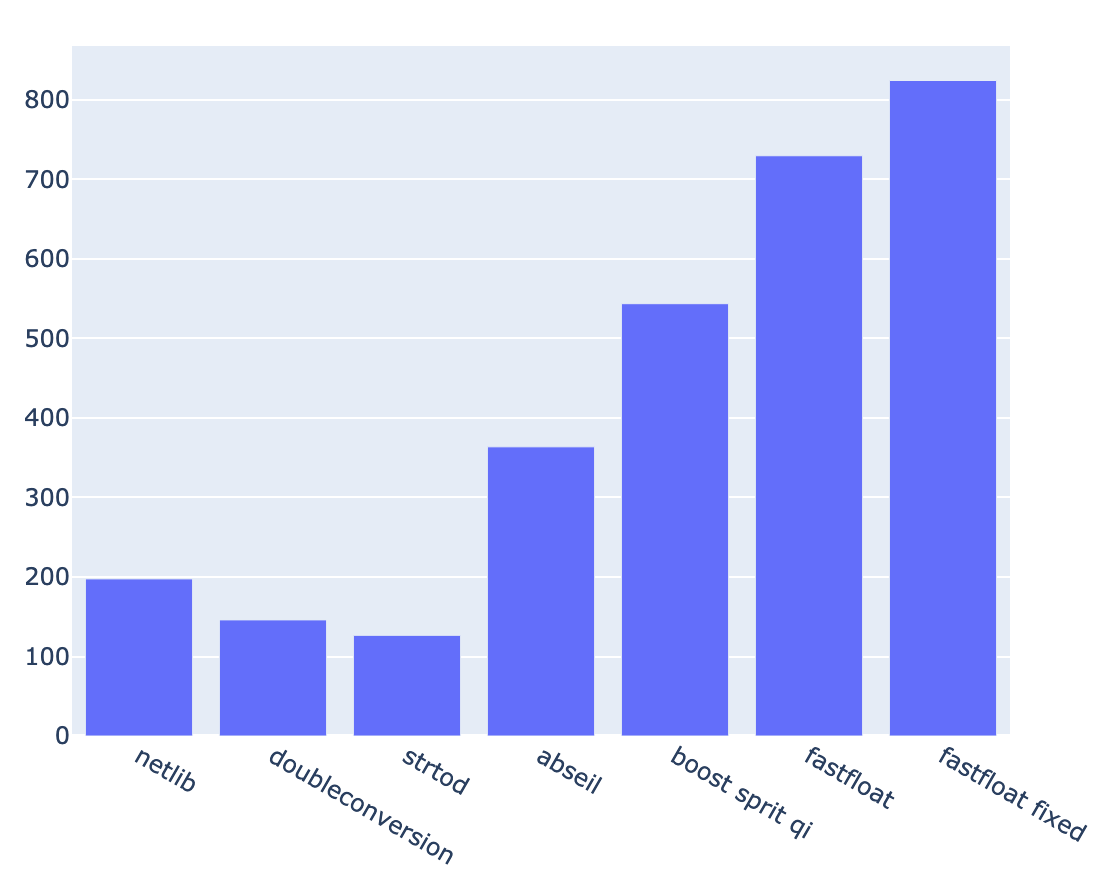
fastfloatが少し落ち込んでますが、全体的な傾向は変わらず。
Qualcomm Snapdragon 720G(Redmi Note 9S) clang 11.0.0
fastfloat (fake) : 919.94 MB/s (+/- 1.7 %) 43.85 Mfloat/s netlib : 199.87 MB/s (+/- 0.7 %) 9.53 Mfloat/s doubleconversion : 119.26 MB/s (+/- 1.0 %) 5.68 Mfloat/s strtod : 29.22 MB/s (+/- 0.3 %) 1.39 Mfloat/s abseil : 241.33 MB/s (+/- 1.6 %) 11.50 Mfloat/s boost spirit qi : 321.52 MB/s (+/- 1.4 %) 15.32 Mfloat/s fastfloat : 575.66 MB/s (+/- 1.0 %) 27.44 Mfloat/s fastfloat fixed : 714.75 MB/s (+/- 1.0 %) 34.07 Mfloat/s
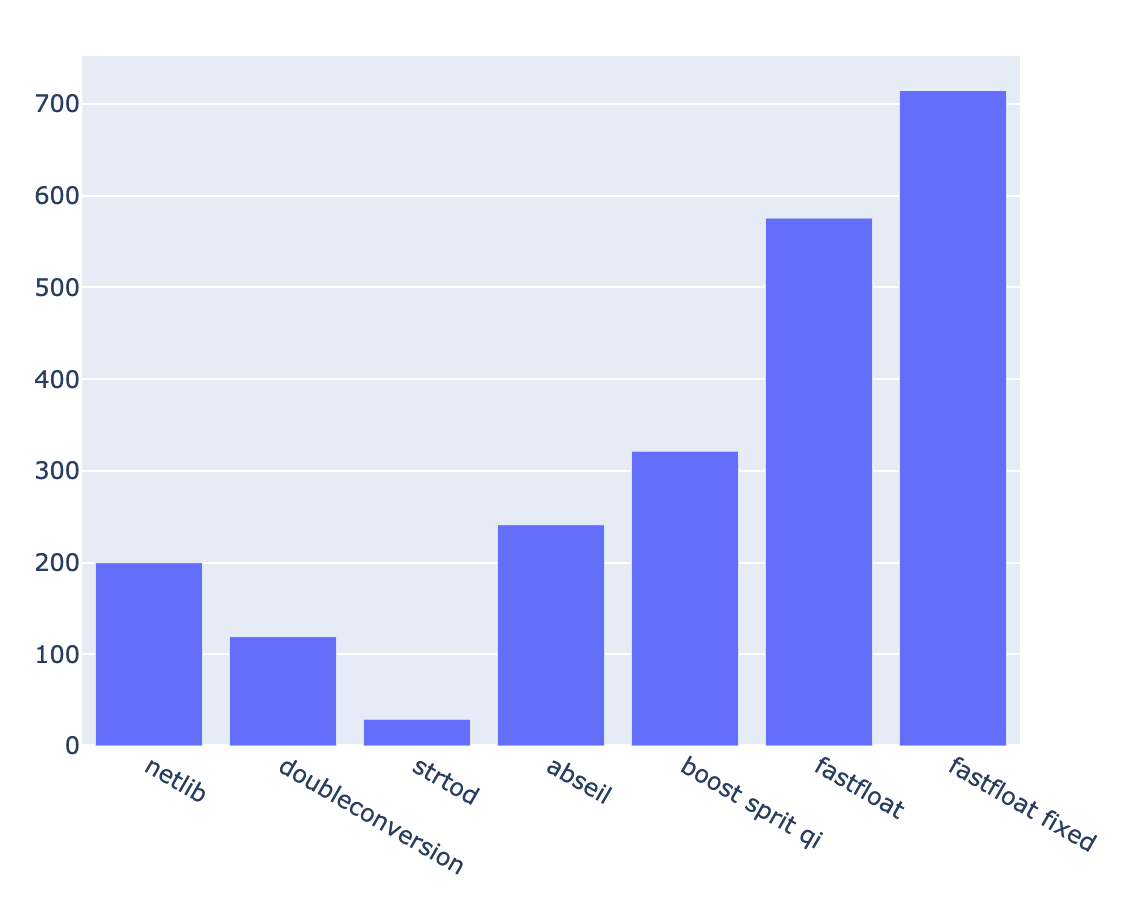
これもTermux上なのでperfがないっぽい。
MacOSXと同じくstrtodが遅い。どんな実装なのか気になる…。
まとめ
全体的な速度で比較するとこんな感じでしょうか。
strtod <= doubleconversion < netlib < abseil <= boost spirit qi << fastfloat < fastfloat fixed
fastfloat圧倒的ですね。
Apache2.0ライセンスだってことが気になるぐらいで、大きな弱点も見当たらないので基本的にはfastfloat使えばいいと思いました。
昔は速いと思っていたdoubleconversionがstrtodと対して変わらないのはちょっとびっくりでした。
ただし、std::from_charsが普通に使えるようになったり、内部の実装が大きく改善することは今後当然考えられるので、あくまで「私が使った環境に依存している」ことはご留意ください。
ベンチマークを試すのは比較的簡単なので、技術選定の際にはご自身の環境での評価をオススメします。